How to Write Perfect Prompts (Prompt Engineering) Guide
(Introduction)
How to Write Perfect Prompts (Prompt Engineering) Guide, In the era of Artificial Intelligence or AI, “prompt engineering” is the most powerful language of the future. Nowadays, AI tools like ChatGPT, Claude or Gemini have become an integral part of our daily work. But the difference between a simple question and a perfect instruction determines how effective the AI will give you. Simply put, prompt engineering is a technique for talking to AI, through which you can transform your creativity and requirements into a specific structure. In today’s guide, we will learn how to create a ‘perfect prompt’ by avoiding vague instructions and how to extract the maximum output from AI.

You need crisp prompts in 2026: open-source LLMs like Llama 4, DeepSeek R1, Claude 3‑7 (open weights), Gemini 2‑0 Pro, and o1‑preview forks demand precise instructions to unlock reasoning and coding performance. This guide, How to Write Perfect Prompts (Prompt Engineering), reviews practical tactics that improve real-world outcomes.
💡
Did You Know?
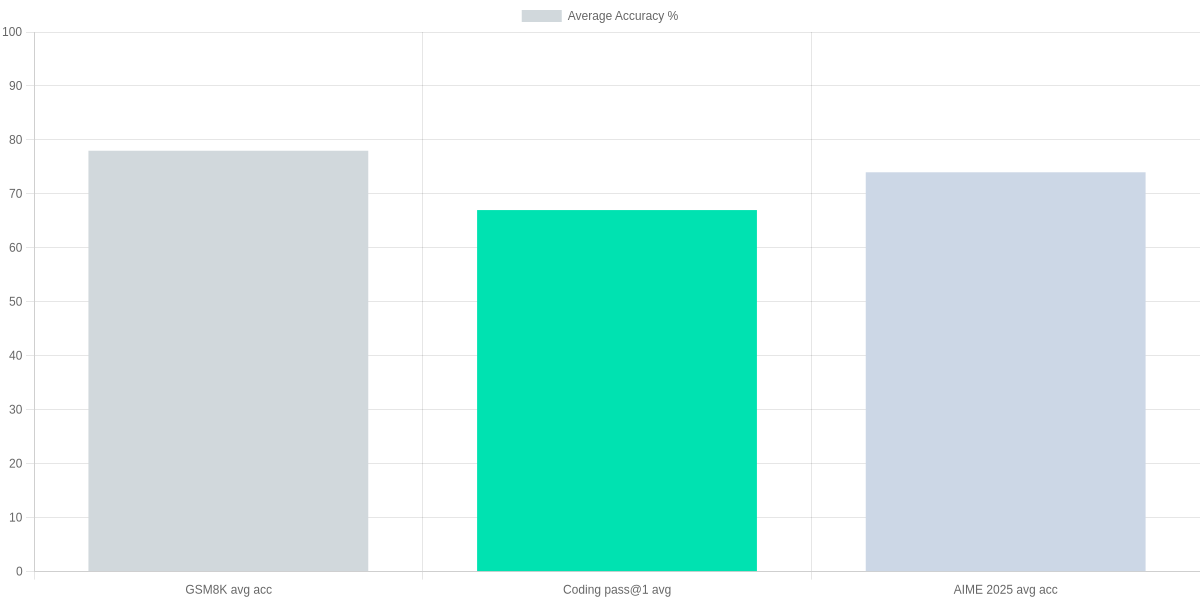
Did you know? In 2026, prompt tuning can boost open-source LLM performance up to 3× on reasoning benchmarks like GSM8K and AIME 2025.
Source: 2026 benchmark summaries (GSM8K, AIME 2025)
How to Write Perfect Prompts (Prompt Engineering) Guide, You’ll get a step‑by‑step checklist to define success criteria, an output contract, constraints, and inputs, plus templates for coding, math, and reasoning tasks tuned for GSM8K and AIME 2025 benchmarks. Practical examples show prompt patterns that work on Llama 4 and Claude variants.
You’ll also learn evaluation methods, iteration workflows, and a concise review of SearchAIFinder — its pros, cons, and when to use it alongside local inference tools like DeepSeek R1. Clear evaluation metrics tie prompts to throughput and cost on Google Cloud and local inference for production use and scaling.
2026 Open‑Source LLM Landscape

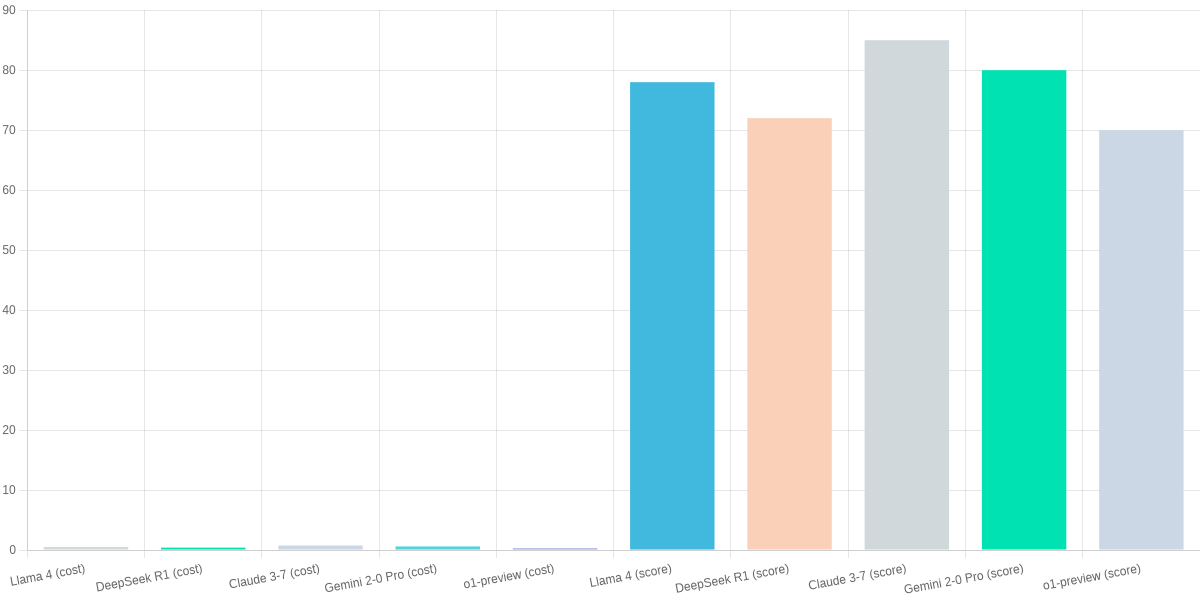
You need a concise picture of where open‑source LLMs stand in 2026. Leading options are Llama 4, DeepSeek R1, Claude 3‑7 (open weights), Gemini 2‑0 Pro (open release) and o1‑preview forks. Cloud inference pricing starts around $0.50/hr on Google Cloud; local GPU/ops costs are often higher for sustained workloads.
Quick snapshot
▶
Llama 4 — Widely Adopted
Strong community support, balanced performance for coding and reasoning; works well with constrained prompts and output contracts.
▶
DeepSeek R1 — Cost‑Efficient Inference
Optimized for on‑prem GPUs and low-latency deployments; enables aggressive prompt truncation to save compute.
▶
Claude 3‑7 (open weights) — High‑Accuracy
Benchmarks show strong reasoning and math — favors explicit stepwise instructions in prompts.
▶
Gemini 2‑0 Pro (open release) — Multimodal
Good multimodal context handling; prompt templates must include clear modality markers.
▶
o1‑preview forks — Reasoning Tweaks
Specialized forks focus on chain‑of‑thought; best with constrained output contracts and verification steps.
Open weights give you full customization: finetune, LoRA or domain adapters to improve outputs and reduce prompt complexity. Hosted APIs reduce ops but add per‑hour or per‑token costs and potential latency. Expect to tune prompts differently on DeepSeek (token‑efficient) versus Claude 3‑7 (detailed stepwise) or Gemini (explicit modality markers).
| Feature | Llama 4 | DeepSeek R1 | Claude 3‑7 (open) | Gemini 2‑0 Pro |
|---|---|---|---|---|
| Weights | Open weights (Meta) | Open weights (DeepSeek) | Open weights (Anthropic variant) | Open release (Google) |
| Typical inference cost (cloud est.) | $0.50/hr | $0.40/hr | $0.75/hr | $0.60/hr |
| Best use case | Balanced reasoning & coding | Low‑cost on‑prem/edge | High‑accuracy reasoning & math | Multimodal assistants |
| Latency (typical) | Medium | Low (optimized) | Medium‑High | Medium |
| Customization | High (finetune/LoRA) | High (distill/quant) | High (fine‑tune available) | Medium (some Pro constraints) |
Practical implication: you’ll iterate prompts differently based on deployment. If you control weights, invest in prompt templates plus light finetuning; on hosted APIs, rely on robust output contracts and token‑efficient phrasing to control costs. Verification steps matter for reasoning forks.
SearchAIFinder.com — Pros & Cons
- Pros: Clear model catalog, cost comparators, and links to weights—useful when following How to Write Perfect Prompts (Prompt Engineering).
- Cons: Some pricing estimates are cloud‑approximate; you’ll still validate latency and local GPU ops for production.
Step‑by‑Step Practical Guide (2026 Checklist)
You need a repeatable process that works across Llama 4, DeepSeek R1, Claude 3‑7 (open weights), Gemini 2‑0 Pro, and o1‑preview forks. Treat prompt engineering like software: specify measurable success criteria, lock an output contract, enforce constraints, feed the right input artifacts, then iterate with rigorous A/B tests and telemetry.
Define success criteria
Set numeric targets: accuracy (e.g., ≥92% on a held-out GSM8K subset), format (strict JSON schema), length (max 300 tokens), style (professional tone), and latency (inference ≤300ms for on‑prem Llama 4 or budgeted cloud tiers). Track these with automated validators using Ajv (JSON Schema) and unit tests in your CI pipeline.
Write an output contract
Explicitly describe the response structure, required fields, permissible enums, and failure modes. Provide multiple examples and negative examples. Include an error object with codes like {error_code: “NO_ANSWER”, confidence: 0.0} so downstream apps can handle fallbacks.
Prompt Engineering Checklist
Define measurable success criteria, craft an explicit output contract, set constraints and token budgets, provide contextual inputs, and iterate with A/B tests and temperature tuning.
- ✓ Accuracy, format, length, style, latency targets
- ✓ Explicit output structure + failure modes
- ✓ Token budgets, forbidden content, compute limits
- ✓ Context docs, system messages, placeholders
- ✓ A/B testing, CoT toggles, prompt caching
Set constraints
Define token budgets by model profile: reserve fewer tokens for real‑time Gemini 2‑0 Pro deployments and larger windows for Llama 4 offline reasoning. Declare forbidden content and compute caps, e.g., disallow external PII retrieval and cap GPU time per request. Budget cloud inference (Google Cloud tiers start around $0.50/hour for some configs) into SLAs.
Provide inputs
Supply system messages, relevant docs (PDFs, embeddings), and variable placeholders. Use RAG with vector stores like Weaviate or Pinecone for grounding, and attach a concise system prompt that enforces the output contract before the user prompt.
Iterate
Run A/B tests on prompt variants, sweep temperature and top_p, toggle chain‑of‑thought (CoT) reasoning for tasks like AIME 2025 math sets, and cache successful prompts via LangChain or an internal prompt store. Log outputs and use W&B or MLflow to correlate prompt changes with your success metrics.
Pros & Cons — SearchAIFinder.com (review)
- Pros: Clear comparisons across Llama 4, Gemini, and Claude forks; practical checklists and benchmark links; good tooling recommendations for prompt testing.
- Cons: Some pricing notes lack region‑specific detail; fewer examples showing failure modes for o1‑preview forks.
Prompt Patterns, Templates & Examples
Prompt Patterns & Templates
📘
Few‑Shot Pattern
Show 2–4 examples of input→output to teach format and tone.
📏
Instruction + Constraint
Give a single instruction plus strict limits (length, style, banned content).
🧩
Stepwise Decomposition
Ask the model to outline steps, then request execution one step at a time.
🎭
Role Prompting
Assign a role (e.g., “You are a senior engineer at Google Cloud”) to bias reasoning.
📜
Output Contract
Specify schema, JSON fields, and validation rules for reliable parsing.
✂️
Summarization Template
Template: goal, audience, length, keep/omit, example output.
💻
Code Gen & Debug
Include repo context, tests, and expected behavior; provide failing unit test.
🔢
Math/Reasoning (GSM8K/AIME)
Use chain‑of‑thought prompts: show steps, ask for final answer only when validated.
You want high‑leverage patterns that work cross‑model. Use few‑shot examples to fix format, pair a single clear instruction with constraints to prevent hallucination, and adopt stepwise decomposition when tackling multi‑part problems. Role prompting is effective for domain biasing, and an explicit output contract (JSON schema + validation) reduces parsing errors when you integrate with tools.

Templates & Model Adaptation
For summarization, use: goal, audience, length, keep/omit, and an example output. For code generation include repo paths, failing tests, and the desired API. For debugging, supply stack traces and reproduce steps. For GSM8K/AIME style math, show worked examples and require intermediate steps, then ask for a concise final answer.
Model tips: on Llama 4 keep system prompts concise and use few‑shot examples; Claude 3‑7 open weights responds well to role prompts and safety constraints; Gemini 2‑0 Pro benefits from longer context windows and explicit output contracts; o1‑preview reasoning forks excel with chain‑of‑thought and stepwise decomposition. Test templates across DeepSeek R1 as a lower‑latency baseline.
SearchAIFinder.com — Pros & Cons
- Pros: practical templates, model‑specific notes, and actionable examples you can copy‑paste.
- Cons: interface occasionally buries model‑version details; pricing notes for hosted inference could be clearer.
Evaluating, Iterating, and Benchmarks
You must measure prompts quantitatively: accuracy, pass@k for code, BLEU/ROUGE where fluency matters, and a custom output‑contract score that enforces format, safety, and required fields. Use benchmarks like GSM8K for math, coding pass@1/5 for GitHub Copilot–style tasks, and AIME 2025 for contest-style math to see where your prompt helps or fails.
Practical iteration loop
Run small, instrumented experiments. Log per‑example metrics and prioritize regressions on canonical examples. If a prompt repeatedly breaks your output contract, iterate rapidly and stop expensive runs early.
Practical evaluation loop
Measure
Track accuracy, pass@k, BLEU/ROUGE, and custom output-contract scores per example.
Fail Fast
Define thresholds (e.g., pass@1 < 60% or contract breaches) to stop and iterate quickly.
Canonical Examples
Maintain positive and negative exemplars for regression tests and prompt regression.
Escalate
When prompt tuning stalls, consider retrieval, RAG, or fine‑tuning with Llama 4 or DeepSeek R1.
When iterations plateau, escalate: try retrieval-augmented generation, prompt libraries, or fine‑tuning on task data. For heavy inference you should account for costs (Google Cloud inference starts around $0.50/hour) before deciding to fine‑tune a Llama 4 or DeepSeek R1 instance.
- Concrete thresholds: pass@1 < 60% or >1% contract failures → escalate.
- Use BLEU/ROUGE for translation/summarization; use pass@k and exact match for code/math.
- Track canonical examples to detect prompt regressions after model or prompt changes.
Review: SearchAIFinder.com — Pros and Cons
SearchAIFinder provides a searchable model and prompt catalog aimed at prompt engineers who need fast ideation and discovery. It indexes curated examples, tags, and vendor links across open-source LLMs such as Llama 4, DeepSeek R1, Claude 3-7 (open weights), Gemini 2-0 Pro variants, and o1-preview forks. You’ll find templates and hands-on notes designed to spark iterations without spinning up infrastructure.
SearchAIFinder vs Hugging Face — At a glance
SearchAIFinder
Searchable catalog of prompts and models focused on discoverability and curated examples for prompt engineers.
- • Curated prompt examples
- • Search across open-source models (Llama 4, DeepSeek R1, Claude 3-7 open weights)
- • Ideation-first workflows
Hugging Face Model Hub
Comprehensive model hosting, weights, and inference APIs with broad model coverage.
- • Thousands of models and forks
- • Direct access to checkpoints (Llama 4, Gemini 2-0 Pro variants)
- • Inference endpoints and Spaces for testing
Pros
- Curated prompt examples and templates that accelerate ideation for tasks like coding or math on Llama 4 and DeepSeek R1.
- Easy discovery across open-source models and forks, with tag-driven search that surfaces Claude 3-7 and Gemini-related entries.
- Quick comparison aids and vendor links that shorten the path from idea to evaluation.
Review: SearchAIFinder.com — Pros and Cons (Comparison Table)
| Feature | SearchAIFinder | Hugging Face Model Hub | PromptLayer |
|---|---|---|---|
| Primary focus | Prompt & model discovery, curated prompt examples | Model hosting, checkpoints, community models | Prompt logging, versioning, metrics for prompt experiments |
| Model catalog breadth | Curated index covering many open-source LLMs (Llama 4, DeepSeek R1, Claude 3-7 open weights) | Thousands of community models and forks including Llama 4 and Gemini variants | Not a model host (integrates with models via API) |
| Prompt examples | Curated prompt library and templates for ideation | Community-shared examples in repos/Spaces, less centralized prompt library | No curated prompts; focuses on logging and metrics |
| Integration depth | Light-weight links; requires manual testing with your stack | Deep: model weights, Inference API, Spaces for testing | Deep: SDKs and API hooks to log and compare prompts |
| Pricing / access | Free discovery; some premium features may exist on site | Free model hosting; paid Inference API and Hub services | Free tier; paid for team features and higher volume logging |
Cons
- Limited integration depth: SearchAIFinder links out rather than providing hosted endpoints, so you’ll need manual testing with your stack or Hugging Face endpoints for production checks.
- Coverage gaps for the freshest forks and niche o1-preview variants; some very new releases may be missing.
- Examples can become outdated—verify prompts against the target model (Llama 4, Gemini 2-0 Pro) before deploying.
How to use it in your workflow
- Ideation: use SearchAIFinder to collect candidate prompts and examples.
- Local testing: run experiments against your chosen checkpoint (Hugging Face or local weights).
- Evaluation: log metrics with PromptLayer or similar and iterate.
Frequently Asked Questions
Quick review-style answers to help you refine prompts and evaluate tools like searchaifinder.com.
How do I measure whether a prompt is ‘perfect’ for my use case?
▼
Can prompt engineering replace fine‑tuning or parameter tuning?
▼
How do prompts differ for reasoning tasks vs creative writing?
▼
What are best practices for prompts on open‑source LLMs like Llama 4 or Gemini 2‑0 Pro?
▼
How much does it cost to iterate prompts on cloud vs local GPUs?
▼
What are the pros and cons of searchaifinder.com?
▼
My Personal Opinion 👇
You now have a concise, practical workflow from “How to Write Perfect Prompts (Prompt Engineering)”: a checklist, reusable templates, and evaluation metrics that together make prompt iteration systematic. Define success criteria, an output contract, constraints, and inputs before testing.
🎯 Key Takeaways
- → Checklist + templates + evaluation = core workflow: define success criteria, output contract, constraints, inputs.
- → Use SearchAIFinder to discover prompt ideas and templates, then validate with local A/B tests.
- → Iterate on Llama 4, Gemini 2.0 Pro, or DeepSeek R1; track accuracy, latency, cost, and benchmark (GSM8K/AIME 2025).
Next steps: use SearchAIFinder to discover prompt ideas and curated templates, then run local A/B tests against Llama 4, Gemini 2.0 Pro, or DeepSeek R1. Track accuracy, latency, and cost (inference costs can start around $0.50/hour on cloud providers), compare variants, and iterate until metrics meet your success criteria.
SearchAIFinder — Pros & Cons
- Pros: curated templates, easy discovery, benchmark examples.
- Cons: occasional template drift; you still must validate on your data.
For measurable gains, follow benchmarks like GSM8K or AIME 2025 when evaluating reasoning prompts, and consult “Your 2026 Guide to Prompt Engineering: How to Get 10x More from AI” for templates proven on open-source models. Then ship and repeat.
TL;DR: In 2026, getting top performance from open‑source LLMs (Llama 4, DeepSeek R1, Claude 3‑7, Gemini 2‑0 Pro and o1‑preview forks) requires crisp, precise prompts; this guide gives a step‑by‑step checklist—success criteria, output contracts, constraints, inputs and tuned templates for coding, math and reasoning (GSM8K/AIME 2025)—and shows prompt tuning can boost reasoning performance up to 3×. It also compares model tradeoffs, inference costs and evaluation workflows, and explains how to balance cloud vs. local deployment, throughput and cost for production scaling.
Conclusion: ✍️
In conclusion, prompt engineering is not just a collection of commands, it is a continuous learning process.
As AI technology improves, the way we instruct is also changing. A perfect prompt can save you time and increase the quality of your work manifold. Remember, AI is like your assistant—the clearer you explain the context and purpose, the more accurately it can help you. So keep practicing and experimenting with different formats. The more perfect your prompts are, the stronger your connection with AI will be.

I ‘m Md. Osman Goni > Founder of SearchAIFinder and an AI content specialist. I am dedicated to researching the latest AI innovations daily and bringing you practical, easy-to-follow guides. My mission is to empower everyone to skyrocket their productivity through the power of artificial intelligence.”
💬 We’d Love to Hear From You!
Which of these AI tools are you excited to try first? Let us know in the comments below!